Variable Selection
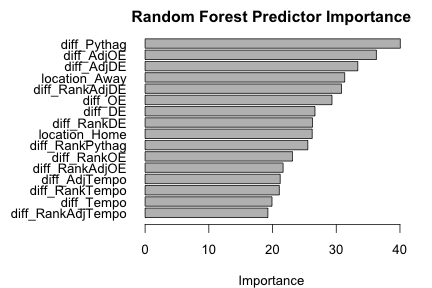
We decided to use the variable importance measure from random forests to decide which predictors to include in our Bayesian logistic regression. The variable importance measure is computed from permuting out-of-bag data: For each tree, the prediction classification error on the out-of-bag portion of the data is recorded. Then the same is done after permuting each predictor variable. The difference between the two are then averaged over all trees, and normalized by the standard deviation of the differences. The predictor with the most decrease in prediction accuracy would have the highest importance.
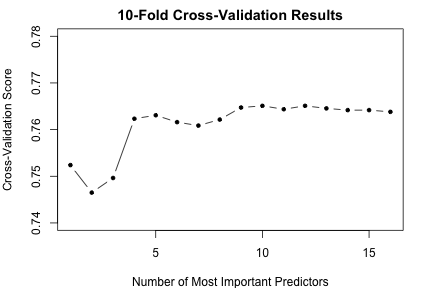
We trained a random forest on the data set using location (home, away, or neutral) and quantitative features that measure the differences in the team statistics per game. We then computed the relative importance of each predictor and iterated over the N most important predictors. For each iteration, we estimated the test accuracy with 10-fold cross validation on the training data, 2015 regular season games. As shown in the chart below, as N increases, the cross-validation accuracy score increases but levels off after N = 5. Therefore, we included the 5 most important features from the random forest as our predictors: diff_Pythag, diff_AdjOE, diff_AdjDE, location_Away, and diff_RankAdjDE.